Having worked in full stack web development and DevOps for over two decades, I’ve experienced my fair share of launches going pear shaped. The following is an overview of Linux commands that have become indispensable in troubleshooting and measuring a web application’s impact on its hosting environment.
Note: Most of these commands are installed by default with popular Linux distributions. However, you may have to install one or two of them.
htop
The eye in the sky
The htop utility provides an interactive overview of every server resource, including CPU, memory, load, and more. It’s the first place I go to when troubleshooting an issue.
To start htop, simply type htop in the terminal window. The visual display will include a list of running processes which can be sorted by clicking on any column heading.
Sorting on the CPU and MEM columns will show what’s consuming the most resources. If CPU is pinned by your web application, you will see that at the top of the list. If needed, you can terminate the process by pressing F9 on your keyboard. Here’s what htop looks like:
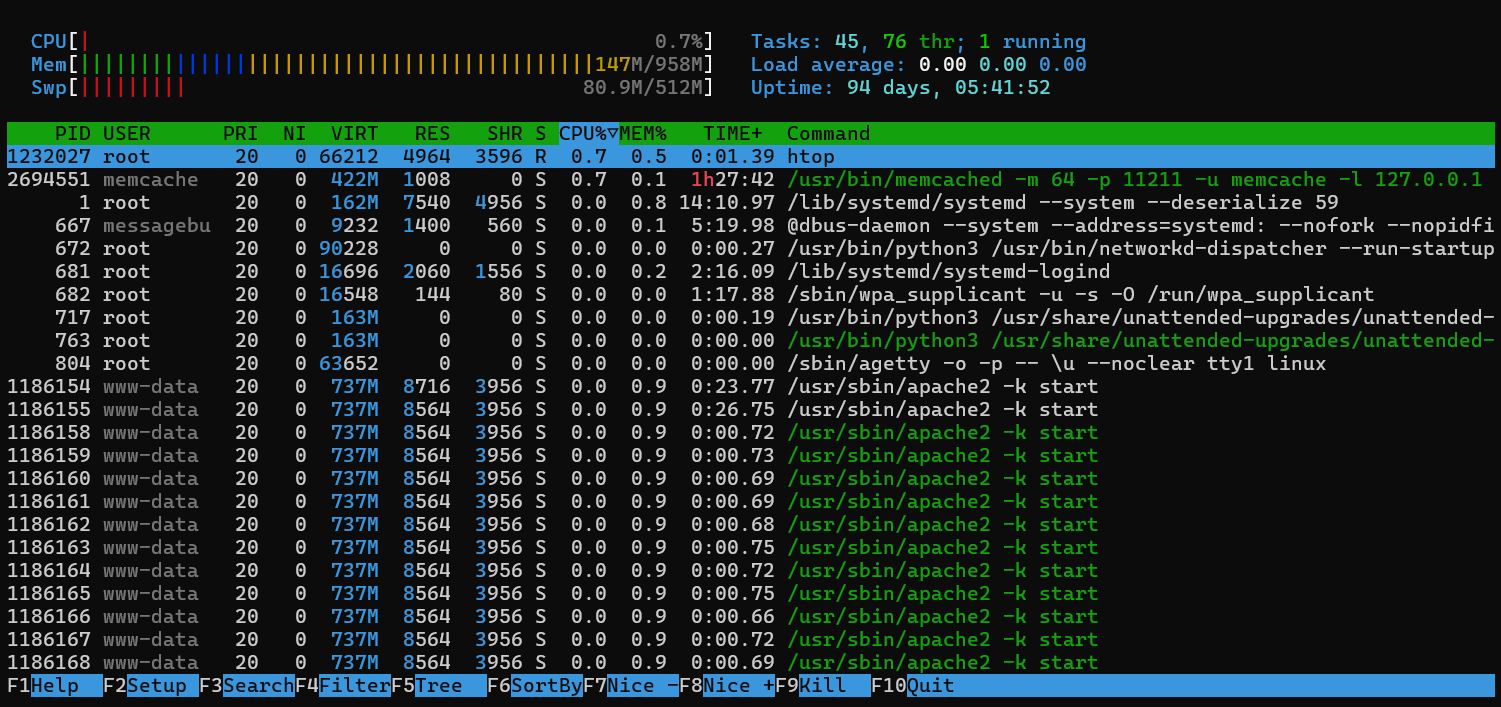
The main thing you want to keep your eye on is Load average and Swap. If load gets too high it will slow down your server. If memory and swap get maxed out, the server will simply start killing processes on its own to free up memory, which you really want to avoid.
ps
Zeroing in on currently running processes
The ps command provides the same list of processes we saw when using htop. Accessing this list directly from the command line gives us some additional capabilities.
I have two use cases for ps. The first is to find out how many web server or proxy processes are running. For example, troubleshooting Apache often requires knowing whether or not it’s over worked.
To see how many Apache procs are running:
$ ps aux | grep -c apache
13
Since ps will produce one line per process, we can find out how many procs are running by piping the result through grep. If the number of processes is higher than expected, we know there’s an issue.
The second use case is finding out whether or not a specific process is running, and if so, how long it’s been running. For example, let say we wanted to check in on a scheduled job running as a cron.
Let’s assume our web application has a component that sends email notifications. The command below will determine whether or not it’s running, and if so, for how long.
$ ps aux | grep mailer
www-data 1468100 0.0 0.8 754888 8272 ? Sl 03:59 0:24 /var/www/site/app/cron/mailer
In the example above, the first timestamp 03:59 is the time the command was started.
vim
Editing files directly on the server
While troubleshooting an issue it may become necessary to edit files on the production server. It’s not advisable to do so, but, sometimes it is the only way to isolate an issue. The vim text editor enables us to edit files in production, and is similar to other editors such as emacs, nano, and vi.
I recommend making a backup copy of the file before you edit it. Also, you will want to refer to a getting started guide for a list of commands.
To edit a file:
$ vim /var/www/site/app/config/mail.config
curl
Web requests from the command line
The curl command is most useful for sending requests to the web application and analyzing the response. It can be used to analyze the contents of a web page to see how it’s being rendered. More importantly, however, we can use it to look at the response headers.
Here is an example of using curl to send a request to a web page to check that a redirect is working properly:
$ curl -I http://jjriv.com
HTTP/1.1 301 Moved Permanently
Date: Fri, 14 Jun 2024 02:40:01 GMT
Content-Type: text/html
Content-Length: 167
Connection: keep-alive
Cache-Control: max-age=3600
Expires: Fri, 14 Jun 2024 03:40:01 GMT
Location: https://jjriv.com/
Notice that the response includes the 301 redirect header. The response also includes the Location header, which instructs the web browser where to redirect to.
iostat
How is the web app impacting disk?
If your web application is connecting to a database you’ll want to know how the SQL queries are affecting the database server. The iostat command will show us how much of the disk I/O is being utilized at that moment. Databases are bound by disk, meaning they can only perform as fast as they can access the data on the disk (until the cache kicks in). If the query is causing too much I/O on the database server’s disks, it will need to be optimized.
It’s not uncommon for a database server to respond differently to queries in staging versus production. PostgreSQL, for example utilizes a query planner that adapts to the amount of data in the database. Just because a query performed well in staging does not mean it will perform the same in production.
The following command will show I/O stats for all disks on the server, including the percentage of time each disk is busy (%util). The integer 1 tells the command to refresh every one second, so we can monitor the disk usage in real time.
$ iostat -d -x
Linux 5.15.0-100-generic (w1sc.pelagodesign.com) 06/17/2024 _x86_64_ (1 CPU)
Device r/s rkB/s rrqm/s %rrqm r_await rareq-sz w/s wkB/s wrqm/s %wrqm w_await wareq-sz d/s dkB/s drqm/s %drqm d_await dareq-sz f/s f_await aqu-sz %util
sda 0.24 6.81 0.06 19.99 0.39 27.92 2.70 21.24 1.07 28.32 0.54 7.86 0.02 15.62 0.00 0.00 0.02 920.55 0.40 0.16 0.00 0.20
The above command uses the -d option to show only disk activity (excludes CPU) and the -x option to include extended stats including %util. If the disk is slowing down the database utlization will be upwards of 100%.
grep
Search log files for specific strings
If you have an idea of what you’re looking for, grep can help you find it faster. The grep command takes a keyword and filename as it’s arguments, and shows you the lines of the file where that keyword reside.
The following example searches an apache log file for an IP address and shows us the lines in which it appears.
$ grep 192.168.3.7 /var/log/apache2/access.log
192.168.3.7 - - [17/Jun/2024:16:42:20 -0700] "GET / HTTP/1.1" 200 34097 "https://jjriv.com/"
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/126.0.0.0 Safari/537.36"
192.168.3.7 - - [17/Jun/2024:12:48:18 -0700] "GET / HTTP/1.1" 301 256 "-" "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15
_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.110 Safari/537.36"
more, less, tail
Sifting through haystacks
When a web application is not behaving as expected we can often find out why by looking at logs on the server. For example, web server logs can tell us if the code is triggering internal server errors or not. Looking at database logs can tell us which queries are taking too long or producing errors. The more, less, and tail commands are all useful for combing through log files.
more
The more command will display the contents of a file one page at a time. It’s more rudimentary compared to the others but can be useful for quickly skimming files. A practical usage case is to combine it with the previously mentioned grep command, to paginate the results of a file search.
$ grep proxy /var/log/apache2/error.log | more
The example above searches the error log for any problems related to apache proxying requests to another server, such as FastCGI.
less
The less command is similar to more, however, it let’s you search for keywords and scroll back through previous pages. It’s a more interactive version of more. I guess you could say less is more 😁
To go through a file one page at a time using less, run the following command. To search within the resutls, type / and then the keyword to search. Use the page down and page up keys to progress forward and backward.
$ less /var/log/apache2/access.log
tail
The tail command is most useful for viewing recent entries in a file, especially if you use the -f parameter to continuously tail a file. Here is an example:
tail -f /var/log/apache2/access.log
You can also combine it with grep to continuously monitor for error messages as they appear:
tail -f /var/log/apache2/access.log | grep ERROR